
seq2seq
seq2seq
超参数
n_step = 5 将每个词统一长度为5
n_hidden = 128 hidden维度
n_class 数据字典的长度
batch_size 每个batch的大小
补充:
关于RNN中参数说明:![https://blog.csdn.net/orangerfun/article/details/103934290]
过程
1.数据与参数的定义
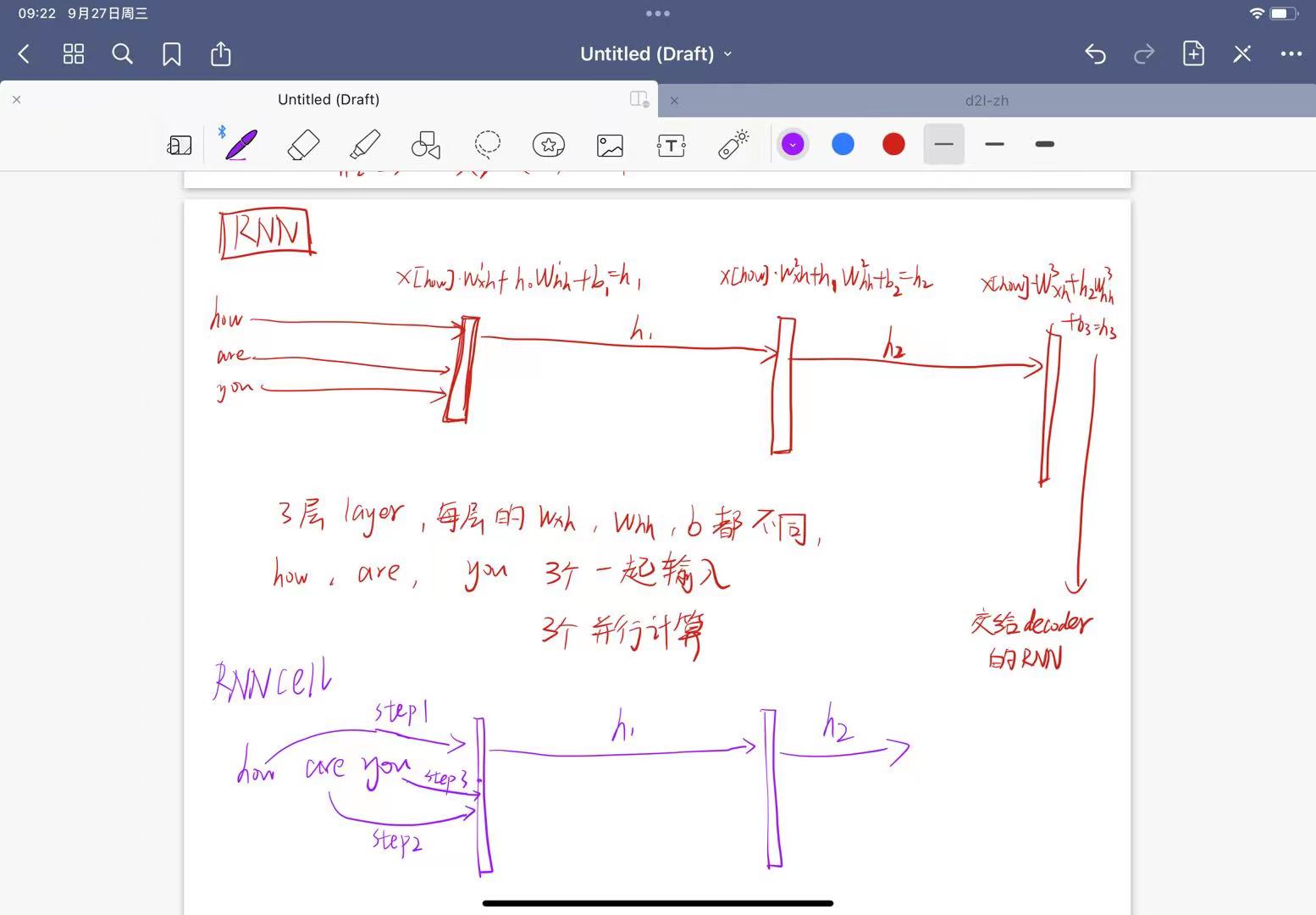
2.model = Seq2Seq( 此时model初始化 encoder decoder 的RNN模型
self.enc_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.dec_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
(此处的dropout不知道是什么意思)
3.定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
4.数据初始化处理
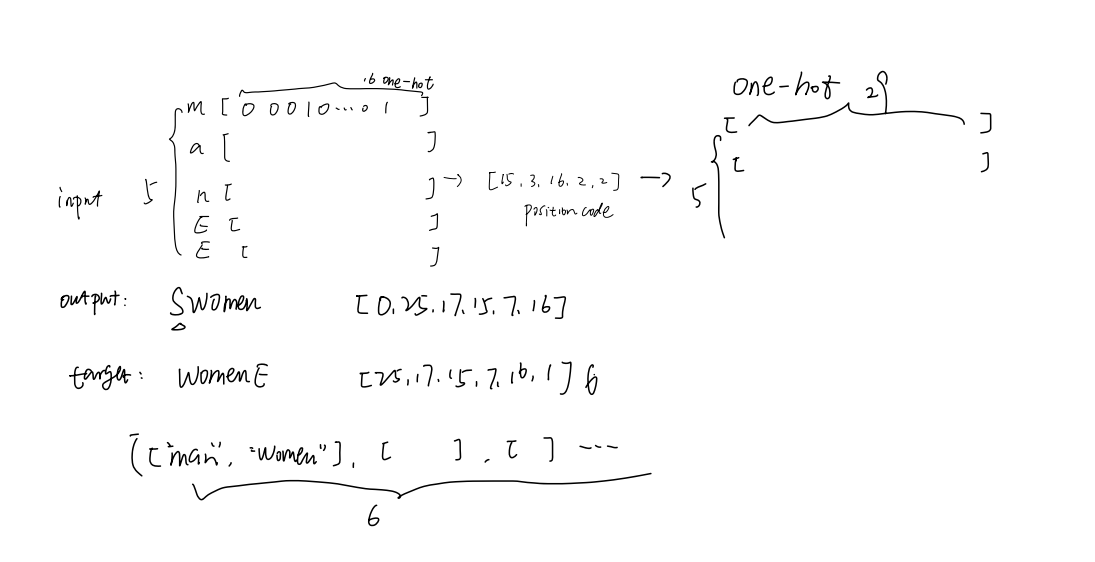
input_batch, output_batch, target_batch = make_batch()
make_batch函数细节:
for i in range(2):
seq[i] = seq[i] + ‘P’ * (n_step - len(seq[i]))
每个词统一长度5 不足补P
input = [num_dic[n] for n in seq[0]]
output = [num_dic[n] for n in (‘S’ + seq[1])]
target = [num_dic[n] for n in (seq[1] + ‘E’)]
开始标记S 以及结束标记E 此时input维度为1x5 因为有5个字符 每个字符对应一个下标index
input_batch.append(np.eye(n_class)[input])
output_batch.append(np.eye(n_class)[output])
target_batch.append(target) # not one-hot
one-hot编码 全部完成后 input_batch维度为 6x5x29 我的理解是append 加一层5x29的矩阵 完事总共6层 5个字符 每个字符的长度29 因为一共29种字符
output_batch为6x6x29
不知道为什么target不用one-hot
5.训练
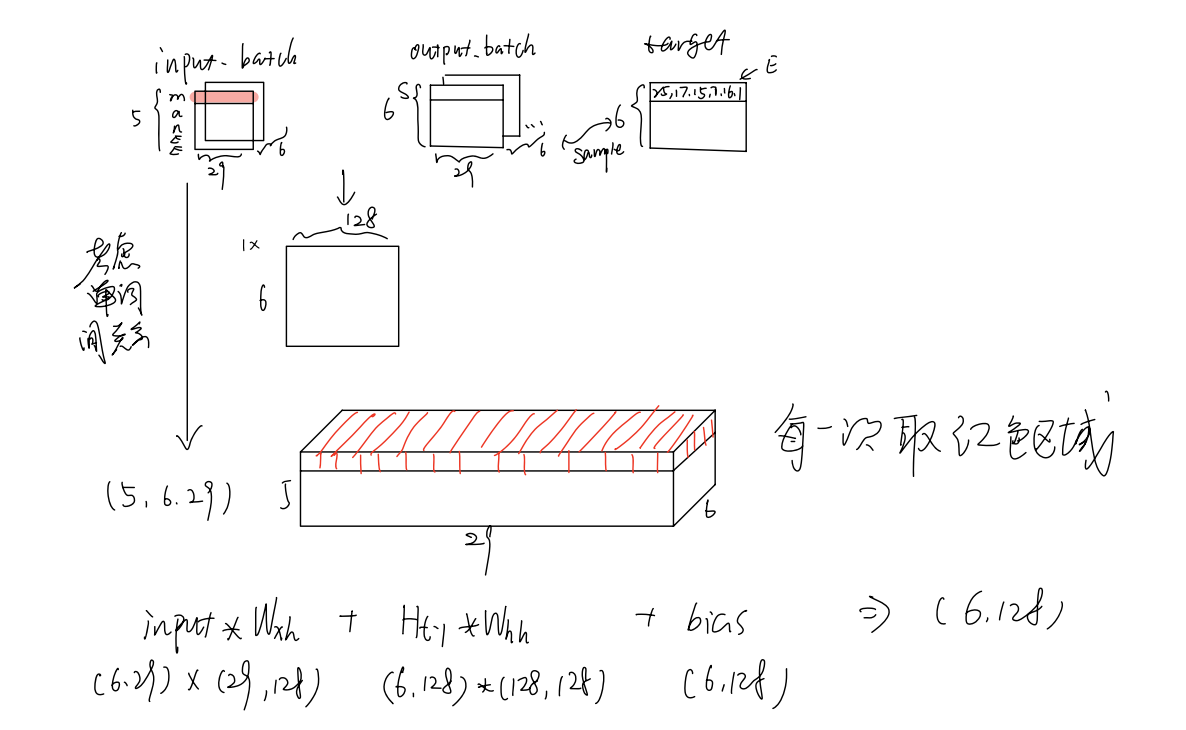
make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, batch_size, n_hidden)
此处默认hidden_layer=1
forward
enc_input = enc_input.transpose(0, 1)
dec_input = dec_input.transpose(0, 1)
交换第一第二维度 此时 enc_input为[5,6,29] dec_input为[6,6,29] 分别为步长(num_step)、batch_size、n_class
_, enc_states = self.enc_cell(enc_input, enc_hidden)
enc_hidden 维度[1,6,128]
enc_states : [num_layers(=1) * num_directions(=1), batch_size, n_hidden] 维度[1,6,128]
将encoder输出的state 交给decoder 作为他的输入
outputs, _ = self.dec_cell(dec_input, enc_states)
outputs : [max_len+1(=6), batch_size, num_directions(=1) * n_hidden(=128)] 维度[6,6,128]
model = self.fc(outputs) 全连接层 将输入[6,6,128]——>[6,6,29]
model 维度[6,6,29] 因此 output = model(input_batch, hidden, output_batch) 维度[6,6,29]
6.计算损失
for i in range(0, len(target_batch)):
# output[i] : [max_len+1, target_batch[i] : max_len+1,n_class, ]
loss += criterion(output[i], target_batch[i])
计算损失值 output[i]维度为6x29 target_batch维度为6x6
不明白criterion是怎么计算的
7.预测
translate(word)
将word one-hot编码 维度为5x29
return torch.FloatTensor(input_batch).unsqueeze(0), torch.FloatTensor(output_batch).unsqueeze(0)
这行代码使用 PyTorch 库将输入批次 input_batch 和输出批次 output_batch 转换为浮点型张量,并在第0个维度上添加一个额外的维度。这通常用于将单个样本转换为批次大小为1的张量 shape为 1x5x29 因为只是一条数据 batch_size =1
- Title: seq2seq
- Author: Jason
- Created at : 2023-09-27 15:12:22
- Updated at : 2023-09-27 16:38:57
- Link: https://xxxijason1201.github.io/2023/09/27/NLP/CS224n/seq2seq/
- License: This work is licensed under CC BY-NC-SA 4.0.